df <- read.csv("https://docs.google.com/spreadsheet/pub?key=0AnKwf3jHs-oIdHZvV0IzaFBNQkowR21wNU4wS2FKb3c&single=true&gid=0&output=csv")
totalName <- "男女計: Total"
total <- df[[totalName]]
n <- (length(total)/12)
y <- 1:n
for(i in 1:n) { b <- (12*(i-1))+1; e <- (12*(i-1))+12; y[i] <- mean(total[b:e]) }
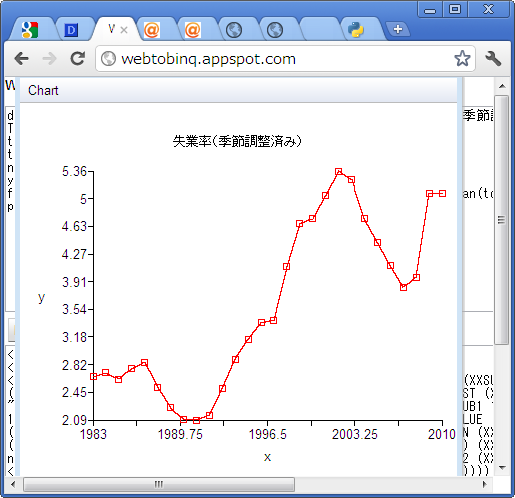
plot(1983:(1983+n-1), y, main="失業率(季節調整済み)", type="l")
(下のはたぶん古い)
df <- read.csv("https://docs.google.com/spreadsheet/pub?key=0AnKwf3jHs-oIdHZvV0IzaFBNQkowR21wNU4wS2FKb3c&single=true&gid=0&output=csv")
totalName <- "男女計: Total"
total <- df[[totalName]]
n <- (length(total)/12)
y <- 1:n
for(i in 1:n) { b <- (12*(n-i))+1; e <- (12*(n-i))+12; y[i] <- mean(total[b:e]) }
plot(1983:(1983+n-1), y, main="失業率(季節調整済み)", type="l")
25~34才の失業率(上とほとんど一緒)
df <- read.csv("https://docs.google.com/spreadsheet/pub?key=0AnKwf3jHs-oIdHZvV0IzaFBNQkowR21wNU4wS2FKb3c&single=true&gid=0&output=csv")
totalName <- "男女計: 25~34"
total <- df[[totalName]]
n <- (length(total)/12)
y <- 1:n
for(i in 1:n) { b <- (12*(i-1))+1; e <- (12*(i-1))+12; y[i] <- mean(total[b:e]) }
plot(1983:(1983+n-1), y, main="失業率(季節調整済み)男女計: 25~34", type="l")
失業率15才~24才、25才~34才と35才~44才を並べる。
df <- read.csv("https://docs.google.com/spreadsheet/pub?key=0AnKwf3jHs-oIdHZvV0IzaFBNQkowR21wNU4wS2FKb3c&single=true&gid=0&output=csv")
sumMonths <- function(total) {
n <- (length(total)/12)
y <- 1:n
for(i in 1:n) { b <- (12*(i-1))+1; e <- (12*(i-1))+12; y[i] <- mean(total[b:e]) }
y
}
y1 <- sumMonths(df[["男女計: 35~44"]])
y2 <- sumMonths(df[["男女計: 25~34"]])
y3 <- sumMonths(df[["男女計: 15~24"]])
plot(1983:(1983+(length(y1)-1), y1, main="失業率(季節調整済み)", type="l")
lines(1983:(1983+(length(y1)-1), y2, type="l")
lines(1983:(1983+(length(y1)-1), y3, type="l")
失業率25才~34才から35才~44才を引く
df <- read.csv("https://docs.google.com/spreadsheet/pub?key=0AnKwf3jHs-oIdHZvV0IzaFBNQkowR21wNU4wS2FKb3c&single=true&gid=0&output=csv")
sumMonths <- function(total) {
n <- (length(total)/12)
y <- 1:n
for(i in 1:n) { b <- (12*(i-1))+1; e <- (12*(i-1))+12; y[i] <- mean(total[b:e]) }
y
}
y1 <- sumMonths(df[["男女計: 35~44"]])
y2 <- sumMonths(df[["男女計: 25~34"]])
plot(1983:(1983+(length(y1)-1), y2-y1, main="失業率(季節調整済み)25~34 - 35~44", type="l")
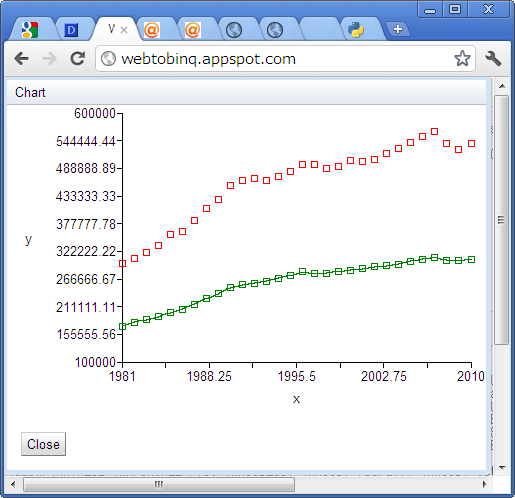
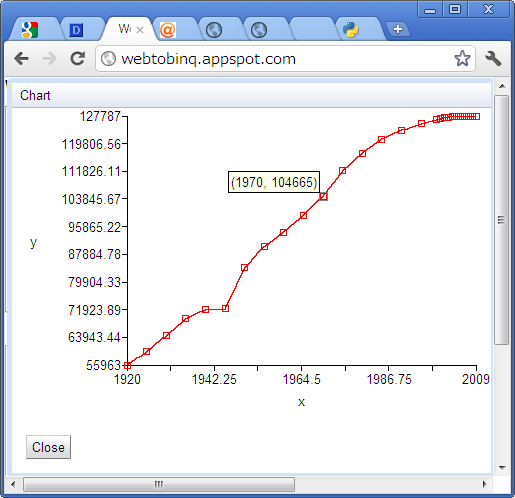
日本の人口全体
pop <- read.csv("https://docs.google.com/spreadsheet/pub?key=0AnKwf3jHs-oIdExXNEhTX3NHWHc3a014eEdxWUs1bHc&single=true&gid=0&output=csv")
plot(pop[["Year"]], pop[["総数"]], type="l")
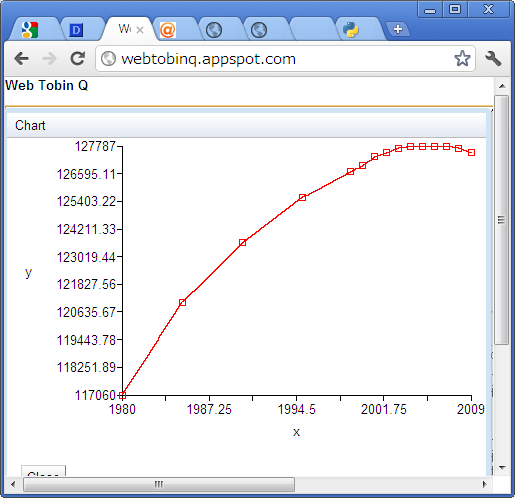
日本の人口1980年以降
pop <- read.csv("https://docs.google.com/spreadsheet/pub?key=0AnKwf3jHs-oIdExXNEhTX3NHWHc3a014eEdxWUs1bHc&single=true&gid=0&output=csv")
year <- pop[["Year"]]
total <- pop[["総数"]]
plot(year[year>1979], total[year>1979], type="l")